Architectural Reinforcement Learning ue5
overview + rationale: intelligent changing worlds
Most game worlds are static. Designers design them, and they don’t change, unless another group of designers change them. One of the main counter-examples is minecraft, where players co-create the game as the game runs. We are attempting to “automate” this (and/or, do it in an alien way). We are working on agents that can create sculptures, structures and settlements. Not only can they create these things (which could be done with procedural generation), they also learn to change their building behaviors (they could learn how to build new kinds of structures, they could learn to build structures that player like, they could learn to build structures that are difficult for players, etc.). The options are quite vast; the goal would be to have these be always learning, always online, consistently interactive in a game world.
{ongoing} #4 learning - navigation system interference
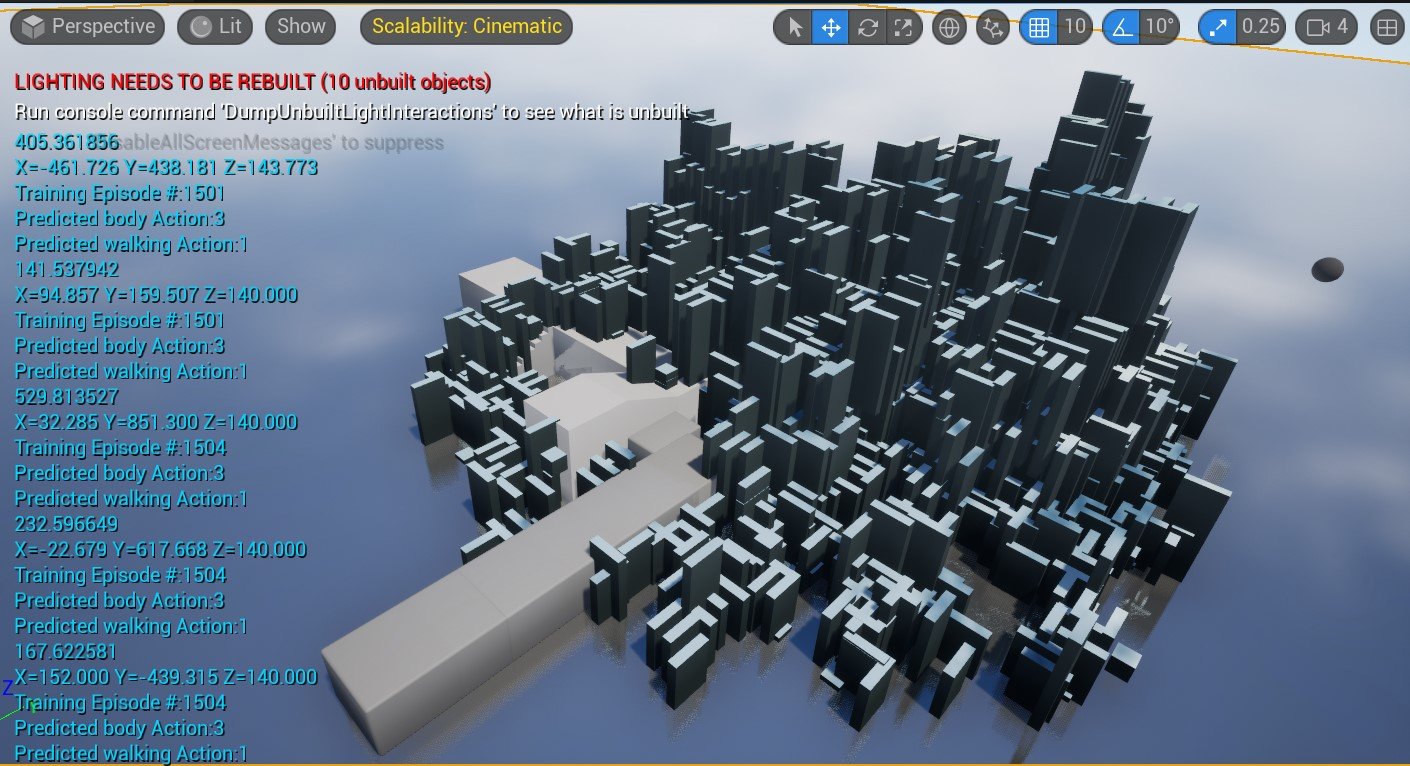
We’ve recently discovered that even thought both systems (DRL and UE5 navigation and block building) are working simultaneously and in tandem, we’ve also discovered some interference patterns. e.g., sometimes, the block building in one place hangs because the navigation system is stuck NOT because the learning system figured out that it was smart to stay in one place.
Consequently, we felt that we had to build a very strict debugging system (still in progress). Now, the learning system indicates its goal with the white debug sphere. And it indicates all possible positions it can take with the small red dots. And, lastly, it does a variety of vertical teleporting behavior to make sure that it never gets stuck. We are currently making sure that this new debugging system works exactly as intended.
#3 Multi Agent Artistic Experimentation
During this phase, we tried various different build configurations for the multiple agent system and it produced a wide variety of intriguing structures/sculptures.







#2 MULTI AGENT hello world
In the examples below, the from #1 is now using a centralized multi agent system (meaning one policy is controlling all agents); theoretically, the policy that develops is the one where when the agents go to select locations, they’re all most likely together to generate a big reward based on height.

#1 drl-ue5 HELLO WORLD
In these early examples below, the learning system and the navigation/block placing system (RL and UE) are all working together. The agent is getting a reward based on how high it gets. I suspected at the time that it was figuring out that it eventually needed to stay in one place and place block beneath itself.
